Software Virtual Texture 学习笔记
Table of Contents
在MegaTexture的基础上,id Software进一步提出了Virtual Texture的概念,这个概念取自于Virtual Memory。与虚拟内存类似的是,一个很大的Texture将不会全部加载到内存中,而是根据实际需求将需要的部分加载;与虚拟内存不同的是,它不会阻塞执行,可以使用更高的Mipmap来暂时显示,它对基于block的压缩贴图有很好的支持。
基本思路是:将纹理的Mipmap chain分割为相同大小的Tile或Page,这里的纹理是虚纹理,然后通过某种映射,映射到一张内存中存在的纹理,这里的纹理是物理纹理,在游戏视野发生变化的时候,一部分物理纹理会被替换出去,一部分物理纹理会被加载。
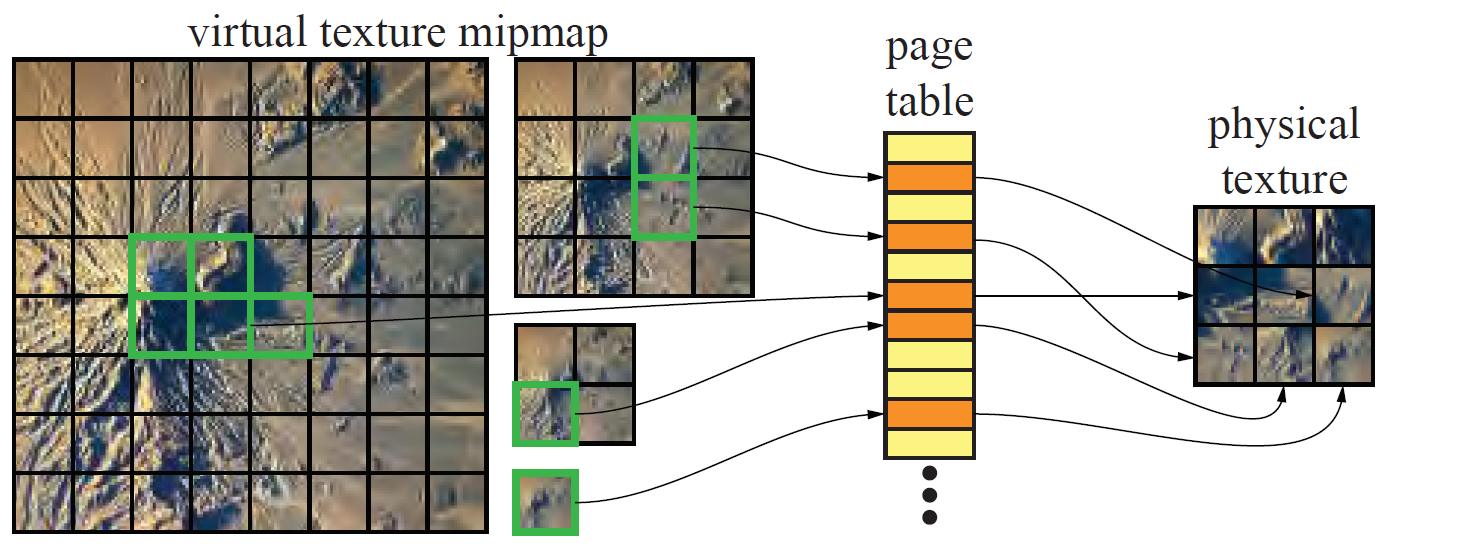
这样的机制不仅仅减少了带宽消耗和内存(显存)消耗,也带来了其它好处。比如有利于合批,而不用因为使用不同的Texture而打断合批,这样可以根据需求来组织几何使得更利于Culling。当然合批的好处是states change变少,LightMap也可以预计算到一张大的Virtual Texture上用来合批。
1 地址映射
地址映射在Virtual Texture中是一个很重要的环节,即是“如何将一个virtual texture上的texel,对应地映射到phyiscal texture上去”。同时还需要处理“假如高分辨率的page没有加载的话,如何获得已加载的相对应的低分辨率的page”
1.1 四叉树映射
使用四叉树主要是为了和Mipmap对应,也就是每个低MIP的Map会对应有四个高MIP的Map,四叉树中只存储加载的Mipmap信息。这里的对应关系就是每个加载的Virtual Texture的Page对应一个四叉树的节点,具体的计算如下:
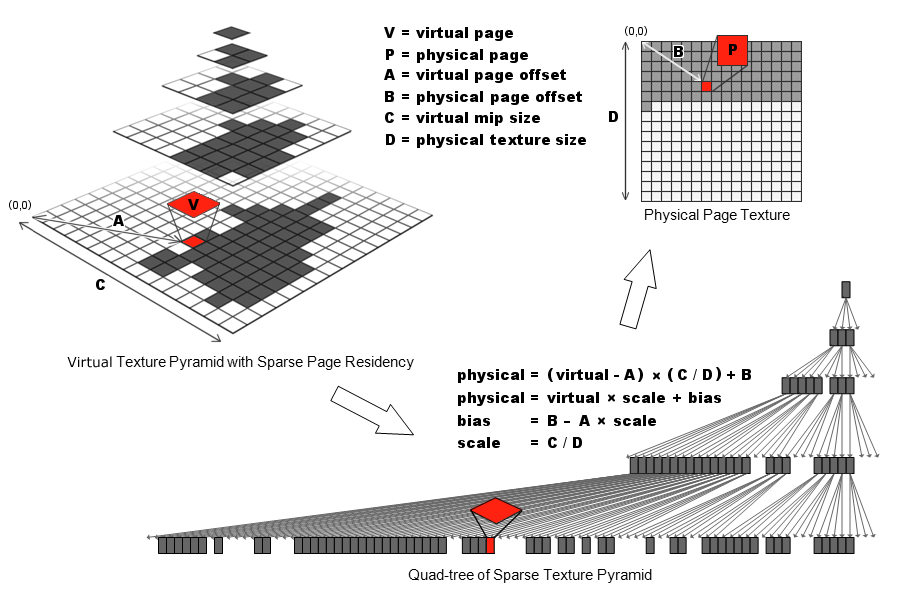
这里存在每个四叉树的节点中的内容就是bias和scale,这样就可以将虚拟纹理的地址转换成物理纹理的地址。如果没有找到,也可以用父节点的地址来得到低分辨率。但是这里要找到对应的节点需要搜索这个四叉树,搜索的速度取决于树的高度,也就是Mipmap的层级,在差的低MIP的地址上效率会比较低。
1.2 单像素对应虚纹理的一个Page的映射
为了减少索引,首先容易想到的就是,为每个虚纹理的Page都存储一份信息,这样就能直接转换了。这个方案就是创建一个带Mipmap的Texture,一个Texel对应虚纹理的一个Page,Texel的内容就是四叉树映射里面的bias和scale。
假如对应的MIP没有加载,存储的就是高MIP的转换信息,这样显然就提高了地址转换的效率。但是这会带来内存增加,因为我们需要每个虚纹理的Page都对应一个Texel。其中bias和scale都是二维的向量,即使设计虚纹理和物理纹理的比例一致,我们也需要至少scale、SBias、TBias三个量,而且这三个量的精度要求很高,至少需要16bit的浮点数精度。如果要达到这样的精度就需要F32*4的纹理格式,那么必然会产生一个巨大的映射纹理,因此需要减小映射纹理的大小。
1.3 双纹理映射
这个方案仍然有一个对应每个虚纹理Page的Texture,但是不同的是,纹理的内容存储的是物理纹理Page的坐标,用这个坐标再去索引另外一张Texture。另外一张贴图的内容才是bias和scale,但不是每个虚拟纹理,而是每个物理纹理Page一个Texel。下图是虚拟纹理对应的Texture:

这样就减少了映射纹理的大小,但是同时多了一次纹理查询。
2.1.4 Page和MIP level映射
总结上面两个基于映射纹理的方案,要么是纹理需要很大的存储,要么是需要多次查询。如果从映射纹理比较大的角度考虑优化,可以考虑适当减少每个像素的大小,这个方案就是从这个角度出发的。在这个方案中,仍然是每个虚拟纹理的Page对应一个texel,但是存储的内容是物理纹理Page的Offset和虚拟纹理所在的MIP level。
这样存储的好处就是,Page Offset对精度的要求没有那么大,用32bit的Texture即可。当然也可以压缩到更小格式的纹理中,如RGB565。这种方案的使用最广泛,基本各家引擎的实现都使用了这种方案。
2.1.5 HashTable映射
这是最直接的方法,好处是节省内存,查询速度快,但是当遇到没有加载的virtual Page的时候,需要多次查询。这个和四叉树还有一个问题,即如何设计一个GPU友好的数据结构。
2.2 Texture Filtering
由于虚拟纹理并没有完整加载,所以各种采样过滤在Page的边界会有问题,我们需要自己设计解决这些问题的方法,适当的使用软实现的采样。
2.2.1 Bi-linear Filtering
这个解决方案比较简单,就是给Physical Page加上一个像素的border。
2.2.2 Anisotropic Filtering
Anisotropic Filtering可能需要更多的相邻像素,假如我们需要支持8倍的Anisotropic Filtering,那我们需要采样步长为4的相邻像素,也就是我们的border要增加到4个像素。增加4个像素的border会增加Physical Texture的大小,但是带来了一个好处,就是适配了block compression。
具体实现可以分为软实现和硬实现,硬实现放到下文的Tri-linear说,这里说软实现。软实现其实就是在Shader中实现Anisotropic Filtering的算法,在决定采样的MIP level的时候,需要把虚纹理相对于物理纹理的比例考虑进去,剩下的就是正常的Anisotropic Filtering。
2.2.3 Tri-linear Filtering
Tri-linear Filtering的实现方案可以分为两种:一种是软实现,一种是硬实现。
所谓的软实现与Anisotropic Filtering一样,在Shader中实现Tri-linear Filtering。也就是说,需要在Shader中计算MIP level,然后进行两次地址的转换,采样两个物理纹理的Page后进行插值。
硬实现的方法是直接给物理纹理生成一个一层的Mipmap,然后利用硬件去直接采样。同样的,对于Anisotropic Filtering,也打开Anisotropic Filtering直接进行采样。这样的好处当然是由于硬件的加速,采样的效率会提升,但是这样同时会导致增加25%的纹理大小,而且由于Mipmap的边界会变成两个像素,对于block compression和超过4倍的Anisotropic Filtering来说,在遇到Page的边界时都会出现问题。
2.3 Feedback Rendering
在Virtual Texture中一个很重要的事情是要有一个可以决定加载哪些Page的策略,这个策略要有一个Feedback Rendering的过程。这个可以设计为一个单独的pass,或者在渲染Pre-Z Buffer,GBuffer的时候同时渲染。渲染生成的这张Texture里面存的就是虚纹理的Page坐标,MIP level和可能的虚纹理ID(用来应对多虚纹理的情况)。
可以看到上图,由于Page的变化在屏幕空间是比较低的,所以Feedback的RenderTexture不需要全分辨率,低分辨率渲染就可以。对于半透明物体或者Alpha Test的物体,在Feedback Rendering的过程中只能当作是不透明物体来渲染,那样就会在屏幕像素上随机产生当前像素的可能结果。
与之类似的,如果一个屏幕像素用到了两个Page,也会是随机出现一种在最后的结果RenderTexture上。这样虽然可以让所有需要的Page都加载,但是可能会遇到另外一个问题,即可能会发生这一帧加载的Page,下一帧的时候被卸载掉,然后再下一帧又要加载,这样会导致物理纹理一直在置换,即便屏幕像素并未改变,物理纹理的Page也无法稳定下来。
为了解决这个问题,需要设计一个调色板,对于半透明物体,间隔出现全透明或者不透明;对于多Page的情况,则需要设计为间隔出现不同Page的结果,这样就能同时加载所有Page,并且保持稳定。但是,如果出现了多层半透明物体的叠加或者多个Page的情况,如何设计一个合理的调色板就变成了一个问题。这里可以考虑为每个像素匹配一个linked list,但需要额外的硬件支持:structured append and consume buffers。
接着就是对这个Feedback的结果进行分析,分析需要将Feedback的结果读回CPU,这里可以使用Compute Shader解析这个结果,然后输出到一个更简单的buffer上去:
这样可以使回读操作更快,处理Page更新也能更快。对于如何更新Page,也需要策略,我们需要尽量不阻塞执行,异步地加载Page,但是对于完全不存在任何一个MIP的Page,我们还是需要同步加载防止显示出错。在异步的过程中,我们要对需要加载Page设置优先级,比如需要加载的MIP level和已经存在的MIP level相差越大的优先级越高,被越多像素要求加载的Page的优先级越高,这里需要设计一个完整的加载策略。
2.4 Texture Poping
由于Page是异步加载的,所以会有延时,当加载的MIP比当前显示的相差很远时,我们渲染会使用新加载的更清晰的MIP,这样我们会看到非常明显的跳变。假如我们用了软实现的Tri-linear Filtering,那么当加载的MIP level跟当前显示的MIP level相差很大的时候,需要做一个delay,等待中间的MIP Page的加载,然后再去更新。对于没有Tri-linear Filtering的实现,就得逐渐更新Page,使得过度平滑。一个可能的方法是,Upsample低分辨率的MIP,直到高分辨率的MIP加载。但是,因为采样的位置其实发生了突变,仍然会出现跳变。
上图可以看到,当分辨率增加2倍之后,结果会发生很大的不同。解决的方案是,先把Upsample的低分辨率Page加载到一个物理纹理的Page,当高分辨率的Page加载好了,插值过度物理纹理的Page,这样采样的位置没有发生改变,只是每个像素的颜色在渐变,就不会有跳变出现了。
2.5 存储和流式加载
这一部分本文会说的比较少,因为这一部分内容甚至比Virtual Texture本身还要繁杂,所以只提一些Virtual Texture比较特殊的部分。
2.5.1 存储和压缩
对于存储和压缩,在光盘或者磁盘上存储的,需要选择一个适合的JPEG等的压缩方式。重点是当加载到内存之后,提交给GPU,根据之前的内容,需要用一个block compression来适配各种Filtering,也可以使用不同颜色空间来进行进一步压缩。
2.5.2 离线烘焙Feedback Data
就如同可见性烘培一样,对于Feedback Data是可以离线烘培的,《Titanfall 2》中实现了这个方案。
2.6 Pipeline
总结一下Software Virtual Texture的流程:
首先执行一个Feedback Rendering,或者从烘培好的Feedback Data中取出当前数据,然后分析需要加载的Page,尝试从内存中找到这个Page,如果没有,就从磁盘或者光盘中加载。然后申请一个新的物理纹理Page,在使用这个纹理之前,假如是之前用过的Page,我们需要先与GPU解绑。确定完之后,把这个Texture转换成一个GPU能用的压缩的Texture内容,并将这块Texture与GPU绑定。其中分析Feedback、Unmap、Transcode、Map过程是可以异步发生的,也就是需要一个Job System去驱动,他们的关系是生产者与消费者的关系。
在Software Virtual Texture中提到的一些内容,在其它的实现中也是需要的,比如Feedback Rendering在Hardware Virtual Texture中需要使用,地址影射在Hardware Virtual Texture和Procedural Virtual Texture中都要用到,接下来描述方案的时候,我就不一一再去说,只提一下他们的方案名字。