Breaking down barriers-Part 1
参考网页: https://www.cnblogs.com/moodlxs/p/10718706.html https://therealmjp.github.io/posts/breaking-down-barriers-part-5-back-to-the-real-world/ Yet another blog explaining Vulkan synchronization how-to-learn-vulkan Vulkan in 30 minutes https://github.com/vinjn/awesome-vulkan
如果您完成了任何数量的D3D12或Vulkan编程,那么您可能花费了大量时间来解决barrier的问题。这些问题可能很棘手:每当改动了一些渲染相关的代码;或者打补丁更新Windows系统之后,引入了新版本的验证层之后,看似正确的验证层却一直抛出新的问题。最重要的是,如果希望使用Vulkan或者DX12之后,GPU性能达到或超过D3D11的水平。IHV(Independent Hardware Vendor)。IHV会一直告诉您,您需要非常小心地使用barrier。
首先为什么我们需要使用barrier?如果我们滥用barrier,为什么事情会变得如此糟糕?如果您已经完成了重要的基于主机控制台的编程,或者已经熟悉了现代GPU的底层细节,那么您可能知道这些问题的答案,在这种情况下,本文并不适合您。但是,如果您没有从中受益,那么我将尽力让您更好地了解在使用barrier时的幕后机制。
什么是barrier
什么是乱序访问
程序在运行时,对内存实际的访问顺序,与程序代码编写的访问顺序,不一定一致,这就是内存乱序访问。之所以会有内存乱序访问这种操作,其产生目的是为了提升程序运行时的性能。但需要注意的是,有时候内存乱序访问不一定能得到正确的想要的结果,尤其是乱序访问产生于多线程对资源的竞争时。
内存乱序访问主要发生在两个阶段:
-
- 编译时,编译器优化导致内存乱序访问(指令重排)
-
- 运行时,多CPU间交互引起内存乱序访问
很多时候,编译器和CPU引起内存乱序访问不会带来什么问题,但一些特殊情况下,程序逻辑的正确性依赖于内存访问顺序,这时候内存乱序访问会带来逻辑上的错误,例如:
1// 示例代码1
2// thread 1
3while (!ok);
4do(x);
5
6// thread 2
7x = 42;
8ok = 1;
在上面的此段代码中,在线程1中,ok初始化为0,线程1等待ok被设置为1后,执行do函数。假如说,线程2对内存的写操作乱序执行,也就是对x赋值后于对ok赋值的话,那么do函数接受的实参,就很可能不为42了。
memory barrier
既然有乱序访问,为了让CPU或编译器在内存访问上有序,memory barrier便应运而生。通过使用 memory barrier。memory barrier之前的内存访问操作,必定先于其之后的完成。memory barrier包括以下两类:
-
- 编译器 barrier
-
- CPU memory barrier
编译器barrier可以用以下的例子解释,假设有以下的C++代码:
1// 示例代码2
2int x, y, r;
3void f()
4{
5 x = r;
6 y = 1;
7}
使用优化选项O2或O3编译上面的代码,(g++ -O2 -S test.cpp),生成汇编代码如下:
1movl r(%rip), %eax
2movl $1, y(%rip)
3movl %eax, x(%rip)
可以看到经过编译器优化之后movl $1, y(%rip)先于movl %eax, x(%rip)执行。避免编译时内存乱序访问的办法就是使用编译器 barrier(又叫优化 barrier)。
Linux内核提供函数barrier()用于让编译器保证其之前的内存访问先于其之后的完成。
在x86-64架构下,内核实现barrier()如下:
1#define barrier() __asm__ __volatile__("" ::: "memory")
把这个编译器barrier加入到代码中:
1int x, y, r;
2void f()
3{
4 x = r;
5 __asm__ __volatile__("" ::: "memory");
6 y = 1;
7}
这样就避免了编译器优化带来的内存乱序访问的问题。
编译器内存乱序访问,是编译器生成的汇编指令就已经是乱序的,而运行时内存乱序访问则是编译生成的汇编指令未必乱序,但CPU是一个乱序处理器(out of order processors)的话,执行指令的先后顺序则可能是乱序的。在乱序执行时,一个处理器真正执行指令的顺序,是由可用的输入数据,而非按照程序员编写的顺序所决定的。依然以上面的示例代码1为例:当有两个CPU同时执行线程1和线程2时,由于是乱序处理器执行代码,所以就算汇编代码是以非乱序的方式生成,依然有可能在线程2中,先执行ok = 1;再执行x = 42;语句。
A HIGH BARRIER TO ENTRY
正如示例代码1中的两个函数,这函数1的执行流程依赖于函数2中对变量ok和x的赋值。在实际的多线程程序设计中,经常会花费大量时间来研究如何表达和解决多线程程序之间的依赖关系。通常做法是建立一个依赖关系图,以表明哪些任务取决于其他任务的结果。该图可以帮助您确定执行任务的顺序,以及何时需要在两个任务(或任务组)之间粘贴同步点,以便较早的启动执行的任务,在第二个任务开始执行之前,能完全完成。下图摘录自Intel的TBB文档:
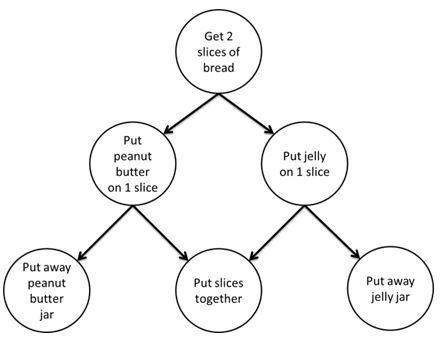
即使从未进行过多线程编程,此图也使任务依赖关系的概念非常清晰:在获得面包之前,是无法把花生酱涂抹到面包上。
如果只有一个人去做拿面包涂抹花生酱的工作。那显然总得先拿了面包,才能接着涂抹花生酱,也就是说,这两个函数在一个CPU上执行,这无所谓依赖不依赖。只有当多个人,也即是说多个CPU上并行执行(或者说,分别执行)拿面包和涂抹花生酱这两项工作才有意义。
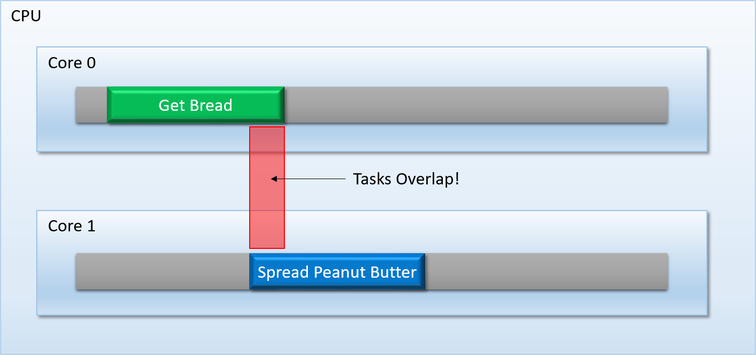
为避免图中所示的此类问题,TBB之类的任务调度程序提供了一种机制,可以强制一个任务(或一组任务)等待,直到上一个任务(或一组任务)完全完成执行。可以将此机制称为barriier,或这synchronize point:
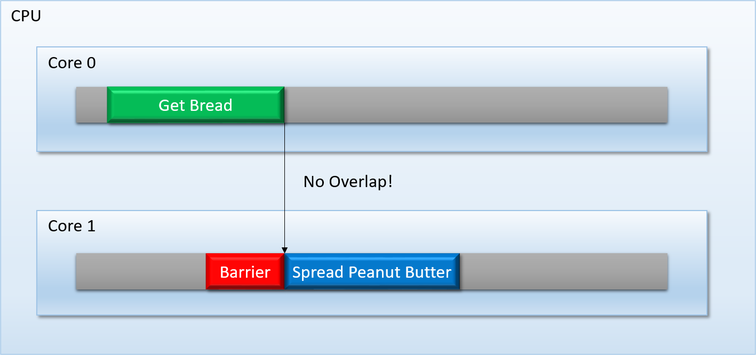
This sort of thing is pretty easy to implement on modern PC CPU’s, since you have a lot of flexibility as well as some powerful tools at your disposal: atomic operations, synchronization primitives, OS-supplied condition variables, and so on.
这种事情在现代PC CPU上很容易实现,因为您具有很大的灵活性以及一些强大的工具可供使用:原子操作,同步原语,操作系统提供的条件变量等。
回到GPU领域
因此,我们已经介绍了屏障的基本知识,但是我仍然没有解释为什么我们在API的设计中将它们与GPU进行通信。毕竟,发出Draw和Dispatch调用,与安排一堆并行任务在不同的CPU内核上执行,实际上并不相同,如果您查看D3D11程序的API调用序列,则该序列看起来非常糟糕:

如果您习惯于通过这样的API处理GPU,那么您会以为GPU只是按提交的顺序,一次执行一个命令就可以了。尽管这可能在很久以前就已经成立,但实际上在现代GPU上,现实要复杂得多。当使用Radeon GPU Profiler进行捕获时,我的Deferred Texturing示例的实际截图如下 :
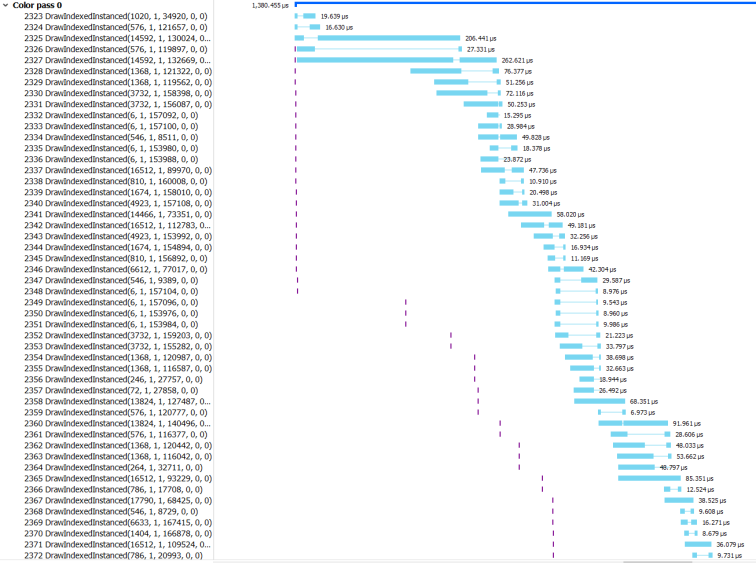
此代码段仅显示了框架的一部分,特别是所有场景几何图形都光栅化为G缓冲区的部分。左侧显示绘图调用,而右侧的蓝色条显示绘图调用实际开始和停止执行的时间。从图中可以看到,这些调用执行的各个过程,有很多在时间上是重叠的!
之所以在会出现在若干对DrawIndexedInstanced函数的调用过程会并行执行的情况。
现代的GPU通常由许多 “着色器核心”(shader core) 组成,这些着色器核心是以并行处理的方式工作的。它们并行地执行可由HLSL、GLSL等高级语言编译而成的着色器程序,以处理来自单次的绘制调用(draw call)提供的若干顶点;处理经由光栅化三角形生成的数百万甚至上千万个片元。但让多个绘图调用也并行执行,使得执行的时间段有所重叠。
现代的GPU,已经能确保,即使在两次绘制调用之间存在一些状态变化时,GPU也能保证多个绘制调用能同时在不同的着色器核心中同时执行。这样子最直接的好处之一,就是可以避免着色器内核发生闲置,使得渲染使用的数据的吞吐量能大幅上升。
他们的GPU仍可以做到这一点。台式机GPU甚至设计了他们的ROP(负责获取像素着色器输出并将其实际写入内存的单元),以便即使像素着色器未按绘制顺序完成也可以解决混合操作。!这样做可以避免着色器内核闲置,从而为您提供更好的吞吐量。不用担心这是否现在还不完全正确,因为我将在以后的文章中逐步讲解一些例子,解释为什么会这样。但是就目前而言,请相信我的意思,即允许绘图和发送重叠通常会提高吞吐量
如果来自绘制调用的GPU线程可以彼此重叠,则意味着GPU需要一种方法,来防止在两个任务之间存在数据依赖的情况下,发生这种彼此重叠的状况。(就比上面例子中的拿出面包和在面包上涂上花生酱)。一旦发生了这种情况时,就需要在CPU上执行操作,并插入与线程屏障(thread barrier)大致相似的内容,以便让我们知道这一组中的若干个线程,何时全部完成工作。实际上,GPU倾向于以非常粗糙的方式执行此操作,例如在启动下一个调度之前等待所有出色的计算着色器线程完成。这可以称为“刷新”或“等待空闲”,因为GPU会在继续运行之前等待所有线程“耗尽”。但是我们将在下一篇文章中更详细地讨论。
缓存很难
希望到目前为止,很明显,至少有一个在GPU上存在障碍的原因:当存在数据依赖性时,阻止着色器线程重叠。这与花生酱和我们之前谈到CPU线程时所布置的面包的情况实际上是相同的,除了核心数量增加到数千。但是不幸的是,当我们谈论GPU而不是CPU时,事情变得更加复杂。
假设您启动了一组运行在CPU上的线程,这些线程将一堆数据写入各个缓冲区,插入线程屏障以等待这些线程完成,然后启动第二组线程,读取第一组线程输出的数据。只要确保您具有适当的内存/编译器屏障,例如使用操作系统提供的同步原语,或者原子操作等等方法,以确保第二个任务的读取操作不会过早发生。而并不需要操心缓存层次结构的具体情况,就都能获得正确的结果。这是因为x86内核上的缓存(通常每个内核都有自己的L1缓存,以及共享的L2和L3缓存)是一致的,这意味着当他们访问不同的内存地址时,它们彼此保持“最新”状态。他们如何实现这一奇迹般的壮举的细节非常复杂,但是作为程序员,我们通常被允许对硬件正在执行的内部体操一无所知。
对于为GPU编写驱动程序的穷人来说,事情并非那么简单。由于各种原因,其中一些可以追溯到其像现在这样不用于通用计算的设备的遗产,GPU倾向于拥有一堆缓存,这些缓存并不总是组织成严格的层次结构。这些细节并不总是公开的,但是AMD往往有很多关于其GPU的公开信息可供我们学习。这是此演示幻灯片50的图表:
AMD_缓存
这看起来与CPU的高速缓存完全不同!L1有两件事,它们以您期望的方式通过L2,但是然后有颜色和深度缓存绕过L2并直接进入内存!还有一个DMA引擎根本不通过缓存!由于实际上每个计算单元(CU)上都有一个L1纹理缓存,并且较大的视频卡上可以有数十个计算单元,因此这里的图也有点误导。还有多个指令缓存和标量数据L1,其中之一在多达4个CU之间共享。该GCN白皮书中有很多详细信息,其中解释了各种缓存的工作方式,以及从着色器进行的直接内存写操作(AKA对UAV的写操作)如何通过其本地L1并最终传播到L2。
由于所有这些高速缓存都没有严格的层次结构,因此这些高速缓存有时可能会彼此不同步。正如GCN白皮书所述,在写入达到L2之前,着色器单元上的L1缓存彼此不相关。这意味着,如果一个调度写入缓冲区,而另一个调度从缓冲区读取,则可能需要在这些调度之间刷新 CU L1缓存,以确保所有写操作至少都写入了L2(缓存刷新指的是缓存)。获取修改后的/脏的缓存行并将其写出到下一个缓存级别或实际内存(如果应用于最后一个缓存级别)的操作)。并作为幻灯片52如描述的那样,当纹理从用作渲染目标变为用作可读纹理时,情况甚至更糟。在这种情况下,对渲染目标的写入可能位于连接到ROP的颜色缓冲区L1缓存中,这意味着除了刷新其他L1和L2缓存之外,还必须刷新缓存。(请注意,AMD的新Vega架构具有更统一的缓存层次结构,其中ROP也是L2的客户端)。
关于AMD硬件的一件很酷的事情是,他们的工具实际上会在发生这种情况时向您显示!这是一个RGP捕获的片段,显示了在大调度完成写入纹理后,我的RX 460上的缓存被刷新(并且着色器线程正在同步!):
RGP_CacheFlush
现在的重点不仅在于解释缓存的复杂性,还在于说明GPU需求壁垒的另一种方式。当您还具有多个可以在其中包含陈旧数据的缓存时,确保线程不重叠不足以解决写入后读取的依赖性。您还必须使这些缓存无效或刷新,以使结果对于需要读取数据的后续任务可见。
挤出更多带宽 随着时间的流逝,GPU越来越专注于计算,但是它们仍然进行了大量优化,以将三角形栅格化为像素网格。这样做意味着ROP最终可能每帧都要触摸大量的内存。现在,游戏必须以高达4k的分辨率渲染,如果您编写每一个都没有透支的像素,则可以达到8294400像素。对于16位浮点纹理格式,将其乘以每像素8字节,对于胖G缓冲区,则乘以每像素30或40字节,您会发现大量带宽消耗仅仅是为了解决所有这些问题记忆一次(通常会多次触摸许多纹理像素)!如果将MSAA添加到混合中,情况只会变得更糟,在天真的情况下,这将使内存和带宽需求翻倍或翻两番。
为了帮助防止带宽使用成为瓶颈,GPU设计人员付出了相当大的努力,在其硬件中构建了无损压缩技术。通常,这种东西是作为ROP的一部分实现的,因此在编写渲染目标和深度缓冲区时使用。这些年来,已经使用了许多特定的技术,但尚未向公众公开确切的细节。但是AMD和Nvidia已经提供了至少一些有关其最新体系结构中增量颜色压缩的特定实现的信息。两种技术的基本要点是,它们旨在利用相邻像素中的相似性,以避免为渲染目标的每个纹理像素存储唯一值。相反,硬件会识别像素块中的图案,并存储每个像素与锚点值的差异(或增量)。Nvidia的块模式可为它们提供2:1至8:1的压缩比,这可能会节省大量带宽!
Nvidia_DCC
那么,这与障碍到底有什么关系呢?这些奇特的压缩模式的问题在于,尽管ROP可以理解如何处理压缩的数据,但当着色器需要通过其纹理单元随机访问数据时,情况不一定如此。这意味着,取决于硬件和纹理的使用方式,在依赖项任务读取纹理内容之前(或可以通过ROP以外的其他方式写入纹理内容之前),可能需要执行解压缩步骤。再一次,当我们谈论GPU和与之对话的新显式API时,这属于“障碍”的范畴。
但是D3D呢? 在阅读了有关线程同步,缓存一致性和GPU压缩的各种问题之后,您希望至少对3个潜在原因有一个非常基本的了解,这3个典型GPU需要障碍来完成我们期望的正常工作的潜在原因。但是,如果您查看D3D12或Vulkan中的实际屏障API,您可能会注意到它们似乎与我们刚才所说的并没有直接对应。毕竟,ID3D12GraphicsCommandList上不存在“ WaitForDispatchedThreadsToFinish”或“ FlushTextureCaches”功能。如果您考虑一下,那么他们就不要这样做。大多数GPU都有许多着色器核心,任务可以重叠,这一事实是一个非常具体的实现细节,对于具有怪异的,不连贯的缓存层次结构的GPU,您也可以这样说。即使对于像D3D12这样的显式API,也没有必要在其抽象中泄漏这种细节,因为有一天D3D12很有可能会用于与行为不如我刚才描述的GPU进行通信(可能已经发生了!)。
当您从这种角度思考问题时,D3D12 / Vulkan障碍将变得更加高级,这主要是为了描述从一个管道阶段到另一个管道阶段的数据流。描述它们的另一种方式是说障碍物告知驾驶员可见度的变化 关于各种任务和/或功能单元的数据,正如我们之前指出的,这实际上是障碍的本质。因此,在D3D12中,您不会说“确保此绘制调用在其他分派读取之前完成”,而是说“此纹理正在从“渲染目标”状态过渡到“着色器可读”状态,以便着色器程序可以阅读”。本质上,您是在向驱动程序提供一些有关资源的过去和未来寿命的信息,这对于决定刷新哪个缓存以及是否对纹理进行解压缩可能是必要的。然后,状态转换隐含了线程同步,而不是在绘制或调度之间显式依赖,这不是一个理想的系统,但是它可以完成工作。
如果您想知道为什么我们不需要在D3D11中手动设置障碍,该问题的答案是“因为驾驶员为我们做了!”。还记得我之前说编译器可以分析您的代码以确定依赖关系并自动生成适当的程序集吗?基本上,这是驱动程序在D3D11中所做的事情,除了它们在运行时正在做!驱动程序需要查看您绑定为输入和输出的所有资源,找出可见性发生变化的时间(例如,从渲染目标到着色器输入),并插入必要的同步点,缓存刷新和解压缩脚步。虽然可以自动获得正确的结果很不错,但是由于以下几个原因也很不好:
自动跟踪资源和绘制/调度调用很昂贵,当您要将渲染代码压缩到每帧几毫秒时,这并不理想。 并行生成命令缓冲区确实很糟糕。如果您可以在一个线程中将纹理设置为渲染目标,然后在另一个线程中将其绑定为输入,则驱动程序在不以某种方式序列化两个线程的结果的情况下将无法确定整个资源寿命。 它依赖于显式的资源绑定模型,其中上下文始终知道每次绘制或调度的完整输入和输出集合。这可以防止您通过无限制的资源访问来完成出色的工作。 在某些情况下,由于不了解着色器如何访问其数据,驱动程序可能会发出不必要的障碍。例如,两个增加相同原子计数器的调度即使它们访问相同的资源,也不一定在它们之间需要障碍。 D3D12和Vulkan背后的想法是,您可以通过使应用程序为驾驶员提供必要的可见性更改来消除这些缺点。这样可以简化驱动程序,并使应用程序以所需的任何方式找出障碍。如果渲染设置相当固定,则只需对障碍进行硬编码,CPU成本基本上为0。或者,您可以设置引擎以构建自己的依赖关系图,并使用该关系图确定所需的障碍。
下一个